 Study Note
Study NoteAppearance
OCR 重构分析
一、原型及需求分析
1、原型分析及拆解
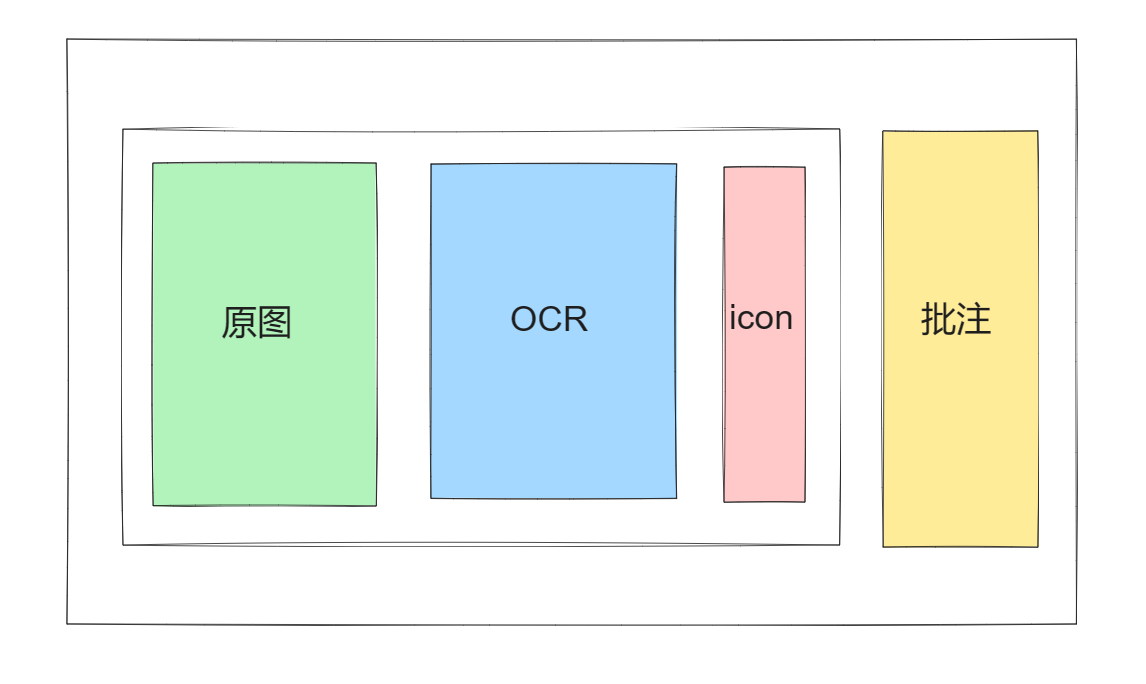
页面主题区域大约分为四部分,分别为 原图 区域、解析出来的 OCR 文本区域、批注 区域、以及根据批注生成在 OCR 文本 对应行高 位置的 icon 区域。
根据交互,其中原图与 OCR 区域的可视效果可随交互的变化进行 显示 和 隐藏。
且,原图与 OCR 内容包含 缩放交互。
2、需求拆解及分析
需求如下:
- 在 OCR 文本区域进行鼠标滑动批注,添加批注后,高亮鼠标选中的 OCR 区域,对应批注应在右侧批注区域显示出来,且在 icon 区域对应 OCR 文本高度的地方生成 icon。
- 点击批注可触发连线,连接到对应批注的 OCR 区域和对应的原图区域(高亮显示)
- 文件有多个,当点击的批注不是当前文件时,要跳转到被点击的批注对应的文件
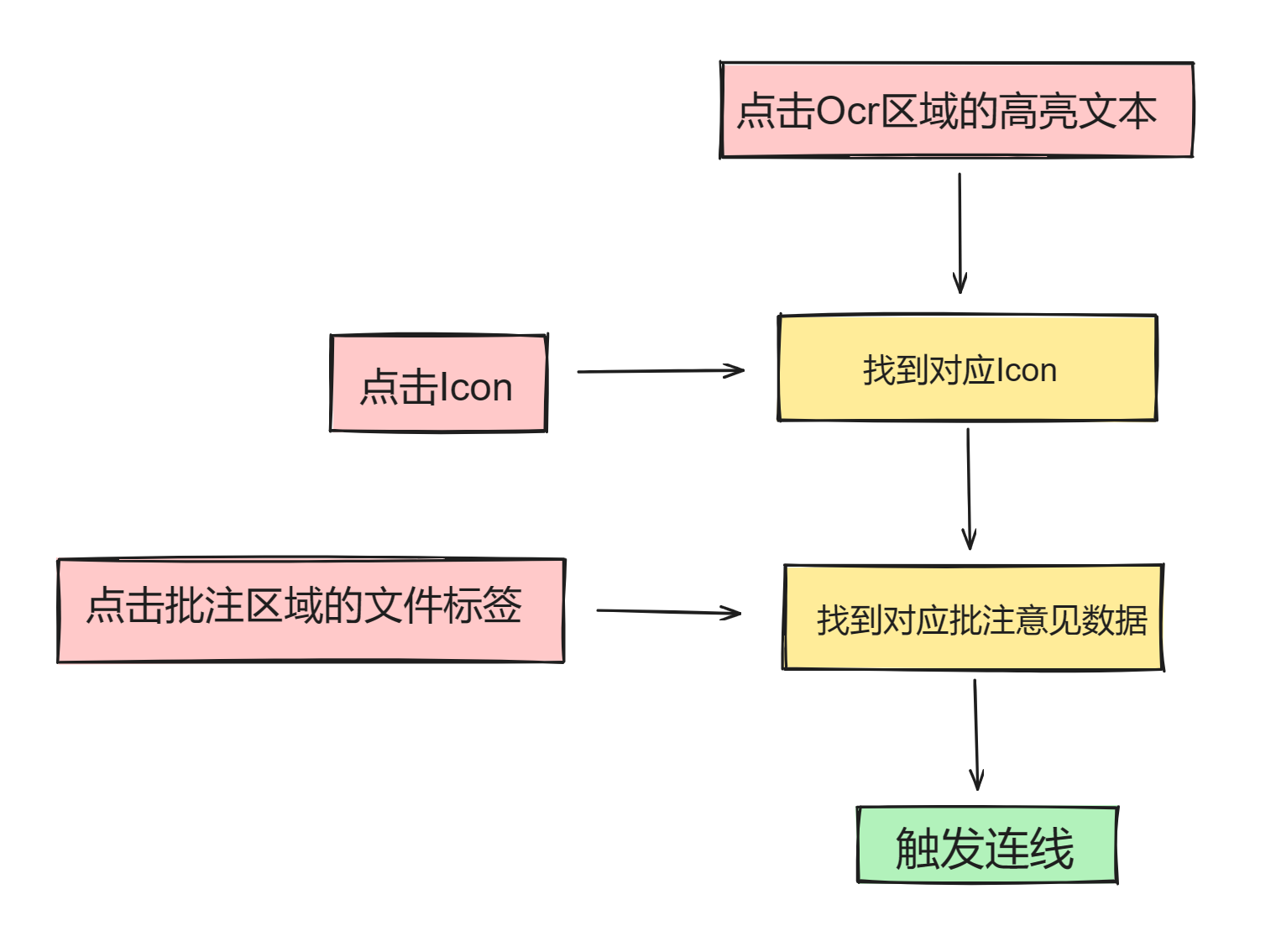
- 批注后,触发连线的方式共有 三种:点击右侧批注的文件标签(即上文所说的点击批注),点击高亮的 OCR 区域,点击 OCR 区域对应生成的 icon
分析如下:
- 一条批注意见可以对应 OCR 上的多个批注位置,一条批注可以拥有不同位置的多个 icon,进而可对应原图中的多个位置
- 一个icon 只对应 一条 OCR 上的批注,注意:icon 存在堆叠情况,此时 icon 可能对应多个批注
- 要尽量保持连线逻辑单一,方便后续维护
新增需求如下:
- PDF 文件,按页码拆分成多个图片,但是批注仍按一个 PDF 文件处理
分析如下:
- 在现有的文件数据结构下,针对 非图片的情况进行处理 (目前仅为 PDF)
- 每个文件种类应有特殊字段标识,接口新增 type 字段
- PDF 与其拆分成的图片的结构关系,按 children 进行处理 (Tree)
二、现有代码分析
1、现有连线逻辑分析
现有的连线逻辑为,点击 OCR 区域内的关键词,触发连线至两侧的原图以及批注区域。
介于 OCR 可以被隐藏的交互,加上需求明显是以意见为主体进行关系设计,选择放弃此路,连线的出发点不应在中间。
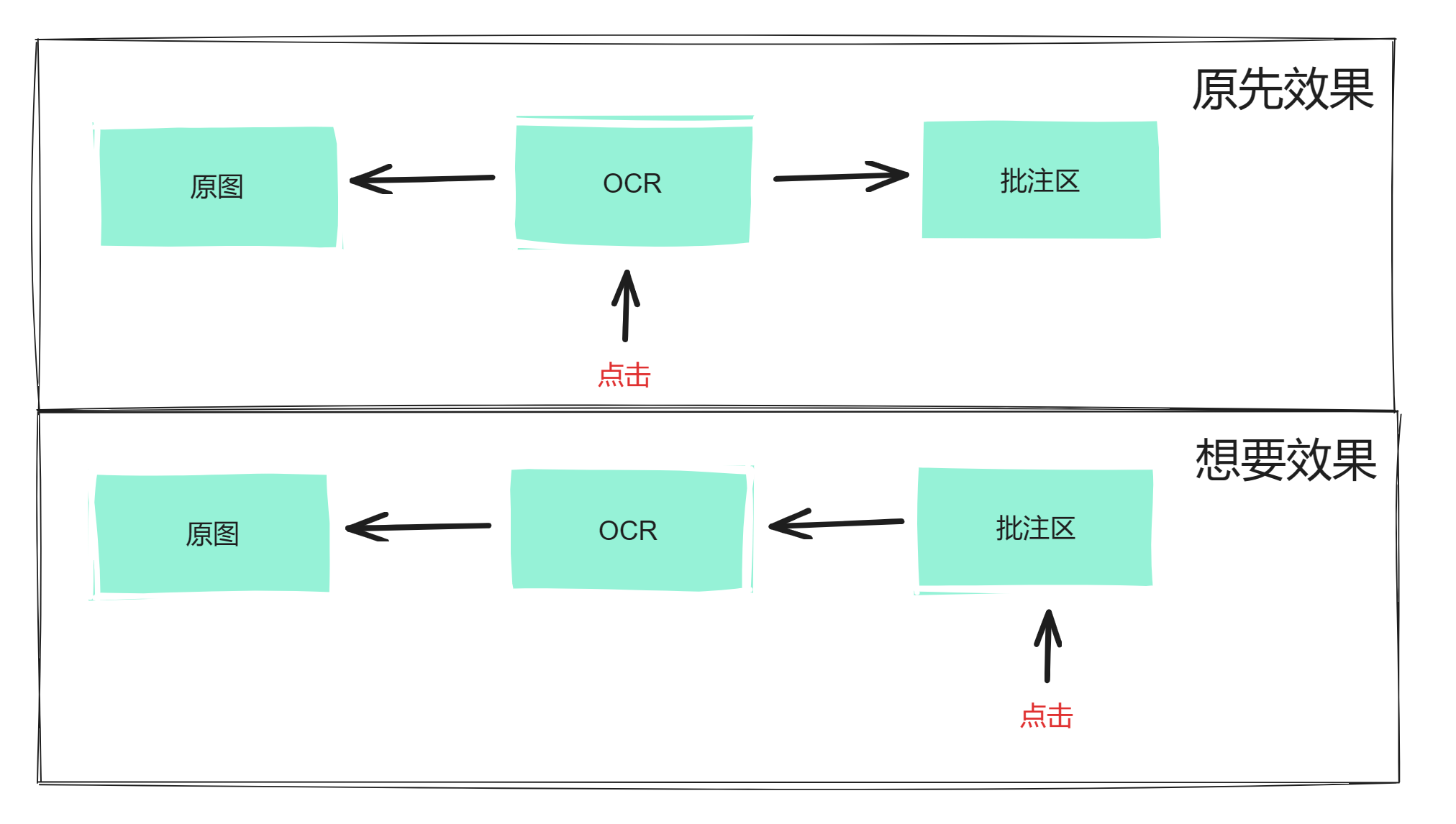
现有的左侧原图区域的视觉交互高亮,与新需求相同,可以复用。
但是原先的连线逻辑为 一对一对一,现在明显会存在 一对多,所以要进行改造
原先代码:
html
<!--原先的高亮 Dom-->
<div>
<Dom :style="传进来的位置信息,利用此信息使得Dom定位至原图对应位置">
</div>
<!--原先的传入对象:
lineWordItem:{
location: {
top,left,width,height
},
word: 关键词信息,
...Other
}
-->
改造后代码:
html
<!--改造后的高亮 Dom-->
<div v-for>
<Dom :style="传进来的位置信息,利用此信息使得Dom定位至原图对应位置">
</div>
<!--改造后的传入对象:
lineWordItem:[
{
location: {
top,left,width,height
},
word: 关键词信息,
...Other
}
...Others
]
-->
2、现有数据内容对应关系分析
意见区域数据:
js
comments: [
files: [],
str: '',
words: [],
selectText: '',
...
]
OCR 区域:
js
ocr: [
[
'str'
],
[
{word}
],
[
'str',
{word}
]
]
借助 自定义属性 data-xxx,利用时间戳当作唯一值,将两个区域连接起来。
即,鼠标选中时,给予被选中元素一个时间戳,然后将时间戳传递到批注意见的数据中存储起来,以此将两个区域关联起来。
icon 关系梳理同理,上文中的自定义属性,可以通过点击事件拿到,所以我们在 icon 的数据存储设计中,也应将这个时间戳考虑进去,以此关联这两个区域。
且,通过这个时间戳,icon 与批注意见也能关联起来。
具体数据结构设计见第三节。
三、数据结构设计
1、批注数据结构设计
批注意见数据存储结构设计如下:
js
comments: [
{
files: [],
// 用来存储高亮 OCR 区域文本
// 应存有对应文件 ID,以及应该被高亮的 OCR 文本的序号
filesWithBg:[
{
fileId: '',
fileBgs:[]
}
],
icons: [], // OCR 时间戳数组
filesWithComment: [
// 文件 ID
// 以此来判断当前批注是否存在于正在被查阅的文件
],
iconsWithPos: {
k:v,
// OCR时间戳: OCR 文本位置 (Array)
},
iconsWithOcrIndex: {
k:v,
// OCR时间戳: OCR Dom的序号 (Array)
}
}
]
2、OCR 数据结构设计
最初的 OCR 的存储结构上文有过介绍,但是明显不适配现在的复杂需要,不合规的对象数组,在遍历和操作其中属性的时候都非常的繁琐且有坑。
再次强调一下代码规范!!!!!
直接将上文中的结构改成最基本的对象数组即可(实际上耗费了1日的工作量)。
最终的 OCR 数据存储结构如下:
js
ocr: [
{
text, // 文本信息
hasBg, // true/false 对应高亮显示
hasComment, // 存放时间戳
word, // 关键词 (保存原有字段,未做出修改)
}
]
3、icon 数据结构设计
icon数据存储结构设计如下:
前提条件:每次切换文件,icon都要重新生成,只生成针对本文件存在批注意见的 icon,并计算好高度将其定位上去。
js
icons: [
{
icon_id,
// 公式:icon 高度 等于 ocr 的 top + ocr 高度的一半 乘以缩放 - 图标自身高度的一半
iconTop,
// 控制此 icon 是否高亮
showIndex: 1 or -1,
ocrId: [
// 上文 OCR 的时间戳
// 可以理解为,此 icon 所管理的 OCR 文本信息凭证
]
}
]
四、新增代码分析
1、连线部分主要流程代码分析
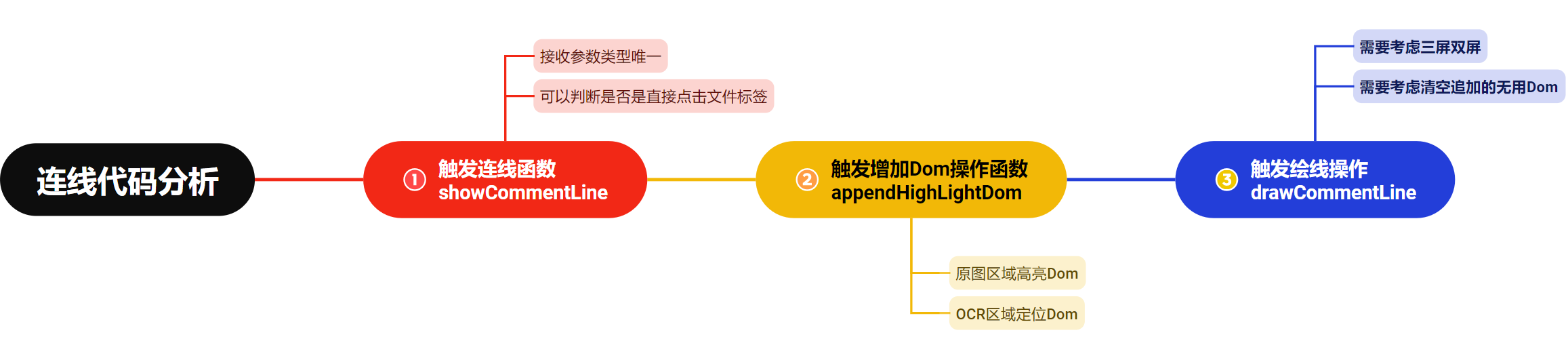
showCommentLine 为触发连线的函数,不管是点击何处,最终都会走到这来。
用 fileId ,将触发操作区分为,直接点击文件标签 or 其他。
js
// obj: 一个批注信息对象
showCommentLine(obj, fileId) {
if (fileId) {
// 如果点击的文件标签并非当前文件,利用文件 ID 进行文件切换
this.changeFileById(fileId)
// 因 一条批注可以对应多个文件,所以利用文件 ID 将 非本文件的内容过滤掉
let curFileOcrIndex = []
// 同时点击批注的同时应该高亮对应位置的 icon 所以应取得 iconIds : Array
// 思路:从过滤好的 OCR 的序号出发,利用 iconsWithOcrIndex 拿到 OCR 的时间戳 组成 iconOcrIds : Array
// 接下来遍历本地图标数组 this.icons ,拿到含有 OCR 时间戳的 icon 的 id 即可,顺利得到 iconIds
// 循环调用封好的函数 changeIconShow,可使得 icon 高亮
let iconIds = []
iconIds.map((i) => {
this.changeIconShow(i)
})
// 接下来需要拿到 OCR 的位置信息,传递给上图流程中的 增加 Dom 的函数,为连线做铺垫
// 思路:借用上边处理好的 OCR 的时间戳 直接利用批注对象中的 iconsWithPos 属性去取即可
// 错误处理:如果没找到位置信息,直接终止流程
let positions = []
if (!positions?.length) {
return;
}
// 将位置信息挂在 obj.position 上,保持处理逻辑统一
obj.position = positions
}
this.lineRemoveOnly();
const commenDom = document.querySelector(`div[data-commenid=c${obj.id}]`)
this.appendHighLightDom(obj, commenDom)
},
appendHighLightDom 顾名思义,作用是 新建 Dom ,不管是原图上的高亮 Dom,或者 OCR 区域的追加 Dom,它们的数据都是在此时整理好的。
连线是基于 leaderline 做的,所以依旧要拿到首尾 Dom 才行。
drawCommentLine 接收两个参数,start 、 end ,都是由 appendHighLightDom 传给它的。
start 为 Array,存储着 OCR 区域新建的 Doms,end 是右侧的批注意见 Dom。
在 drawCommentLine 要做两件事,其一为二次触发要取消连线,其二为要根据当前分屏(三屏,双屏)情况,做好对应的连线数据。
有三组 Dom 数据,分别为:函数入参 start、end,还有我们可以在页面中获取的 highLightDoms。
只需要根据 curMode(当前模式,也就是分屏情况),来调整连线的首尾节点即可。
针对重复触发连线,因批注意见节点是一直存在于多种情况下的,所以给其添加 data-commenid ,并在 data 中存储上一个触发连线的批注意见 id 。
两者比对,即可获知是否为重复触发。
2、连线部分其它流程代码分析

showOcrCommentLine 为点击 OCR 文本触发函数,由上文可知,我们在此可以拿到 OCR 文本对应的时间戳。
由上图可知,我们要去触发图标连线的函数,所以我们用时间戳,去图标中去寻找那个要被连线的图标,之后触发图标连线。
这里将寻找的逻辑抽出去了,形成:findIconPos 函数
showIconLine 为点击图标触发的函数,接收一个 icon 对象。
根据接收到的 icon 对象,先去执行高亮逻辑,判断此时应高亮 or 取消高亮。
这里要注意一个 icon 可能对应多个批注,所以不应 boolean = !boolean
接下来去整理我们 showCommentLine 函数需要的 obj 对象,将其传入即可。
主要逻辑为,根据 icons 下方的 ocrId ,去 comments 的 icons 里 拿去对应的 comments 对象。
注意 icons 下方的 ocrId 为数组,每次触发其中的 第 i 条 数据,取消连线的时候,继续传入 第 length - 1 条 ,即最后一次的数据,取消连线。
3、添加批注代码分析

首先是通过监听鼠标抬起(mouseup)事件,获取到选中文本所在 Dom 节点 的函数 getSelection。
这里用到的是 Window 对象下的 getSelection 方法。
选中多行文本的情况可以使用这种方案进行处理,可以获取到多个 Dom 元素。 方案:鼠标选中获取页面多个 Dom 元素
这里要注意的点就是,不管是一个还是多个 Dom ,都将结果处理成数组,类型统一方便后续进行操作。
getRectOverDom 函数,接收上文中的 Dom 数组,对数组中的 Dom 元素 进行遍历处理,最终拿到 左、上、右、下 ,也就是被选中 Dom 的最外层边框。
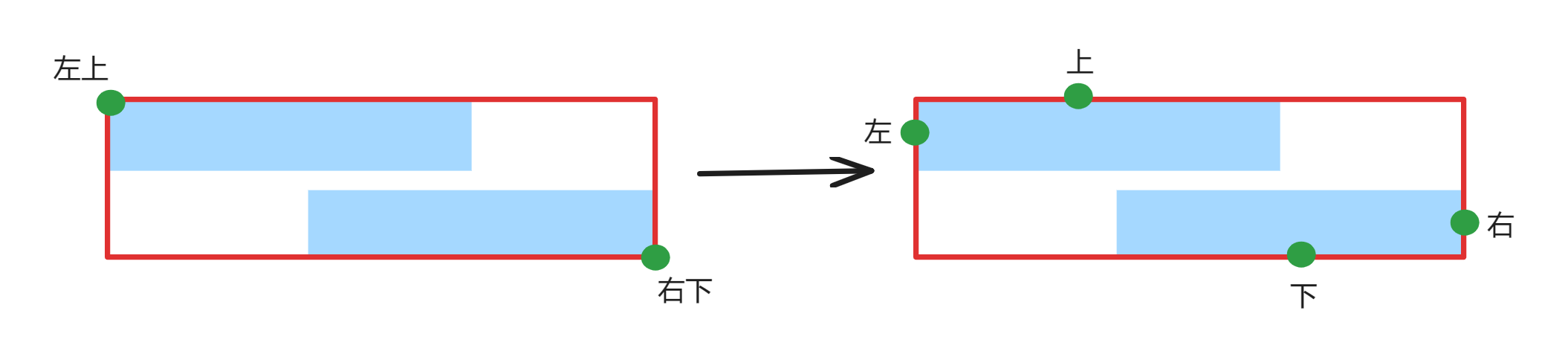
除此之外,在遍历 Dom 的时候,还会通过 getSelectDomIndex 多拿一个 OCR Dom 的 index 值,用来做高亮用。
addCommentWithPosition 为添加批注的主要函数,包含正常添加批注和关联意见批注两种触发方式。
正常添加批注分为 img 和 pdf(切成 img)两种情况。
需要处理的点在于,针对非 img 的文件 id 的存储,应该存被切成的 img 的 id。
关联意见的添加,就是添加一个一模一样的批注,仅有 OCR 的位置及文本不一样,完后利用意见更新时去重的操作将其处理成一个就行。
五、细节功能设计
icon 定位方案
需求:尽量保证行与 icon 高度上一一对应。
思路:通过选中的 OCR 文本 Dom 能拿到一个 top 值,用这个值,加上文本高度的一半,就能找到这条文本的中心高度,icon 应与这个高度对齐。
代码流程: generateIcons
首先监听图片的加载事件拿到图片高度,赋值给存放 icon 的 Dom ,以此来保证 icon 跟 OCR 区域可以同步滚动,且通过图片的 naturalWidth 和 clientWidth ,可以算得此时的缩放比。
其次用当前文件的 id ,从 comments 里将对应的 OCR 的时间戳取出。
用这些时间戳,进行 icon 生成。
最后,在新生成 icon 的时候,对 icon 的 top 进行计算,计算方式如下:
iconTop = OCR 的 top + OCR 文本高度的一半 * 缩放 - 图标自身高度的一半(7.5)
接下来去遍历现有的 icon,比对其 iconTop 与新生成的 iconTop 是否有 15 px 的差值 (因为icon 的高度为 15 px)如果小于15,就将两个 icon 的数据进行合并。
三屏、双屏切换时位置缩放计算
首先三屏、双屏的时候,图片的缩放比是不一样的,这会影响我们涉及 Dom 缩放的操作。
涉及到的有:
- 点击连线的时候 OCR 区域的Dom 和原图处高亮的 Dom
- OCR 文本区域的文字也受缩放比来控制其显示大小
思路:图片加载完之后,可以得到一个缩放比,利用 OCR 结果返回的 position 信息,与缩放比进行乘积,可得出想要的位置信息。
所以 comments 中存储的,一定要是 OCR 中的 position,或者对标 OCR 中的 position 计算出来的位置信息 (大坑) 。
在每次切换三屏双屏的时候,重新计算缩放比,然后生成出来的 Dom 就会是符合当前情况的了。
算缩放比的时候,最好是在即将渲染在页面的时候,再去乘,否则存储过程中会有精度丢失的问题。