 Study Note
Study NoteAppearance
OCR 文本拆解
接上文 【重构之后】
上次重构,由于 种种原因,写的不是很完善,比如在鼠标划取选择文字的时候,就只能获取到一行的文本,不能再继续细化了。
我们的产品老师当然是不满意的,那么只好拿起手中的键盘继续敲咯!
先想后干
我们目前的 dom 结构如下:
html
<div class="ocr">
<div class="ocr_content" >
<div v-for="(item, index) in ocr.arr" :key="index">
{{ item. word }}
</div>
</div>
</div>
word 为一个不定长字符串,要拆解成单个文本,那直接遍历出来不就妥了。
html
<span v-for="str in item.words">{{str}}</span>
效果也是如我们所想:
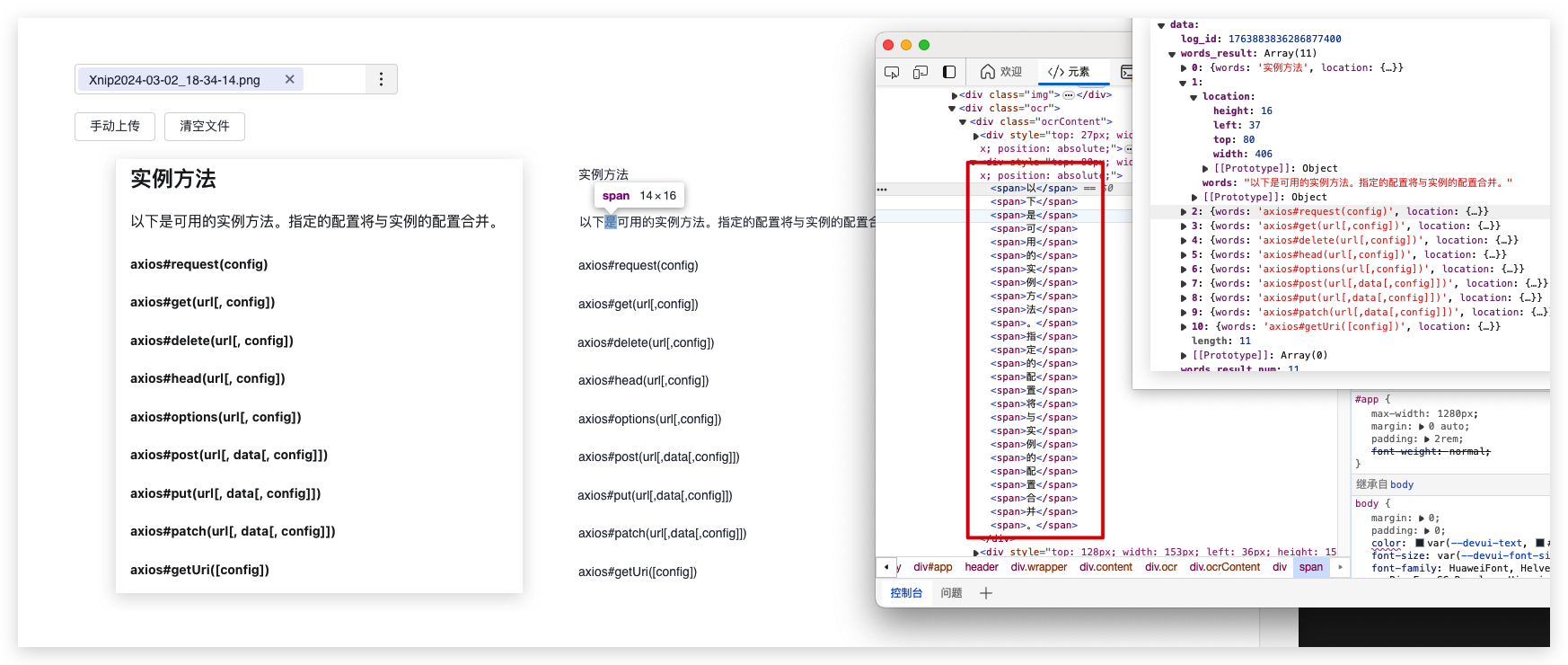
接下来如果能取到所划取文本的 left,就算是大功告成,因为 top 的值可以直接取父元素的。
由于我们是可以拿到被划取的 dom 的,所以我们可以用 offsetLeft 拿到其相对于父元素的偏移量。
还不知道怎么拿 dom 的,去看这里,我总结过:鼠标滑动获取 dom
note.wangez.site -> 代码人生 -> 实用工具 -> 鼠标滑动获取 dom
这里我们取数组中的第一个就好:
js
console.log('left:', allSelected?.[0].offsetLeft)
也是顺利取到了:
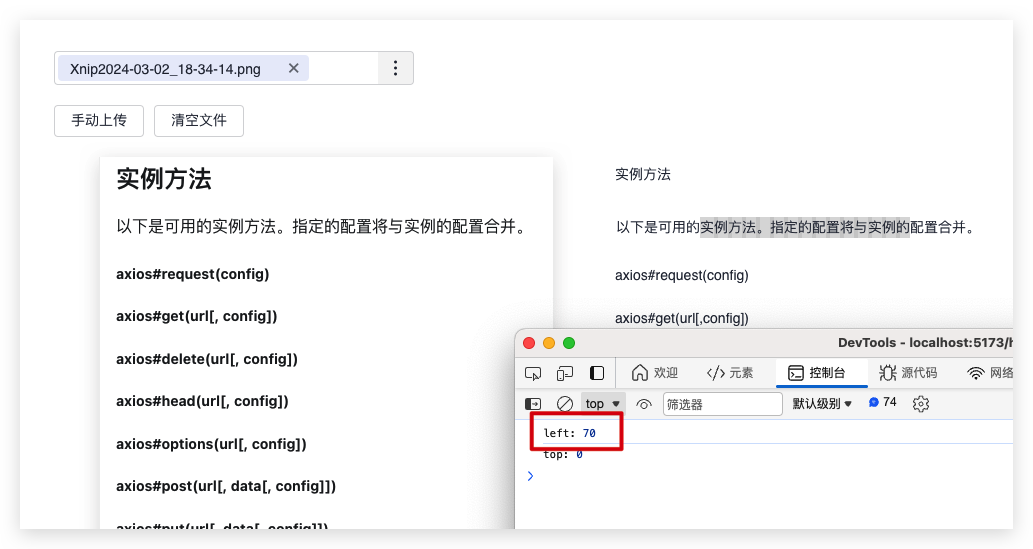
至此完工!
顺便说下
这次的 demo 采用的是百度的 ocr 接口,去百度智能云注册后,用 AK 与 SK ,获取到 access_token 之后拿着 token 去调用 ocr 接口就可以。
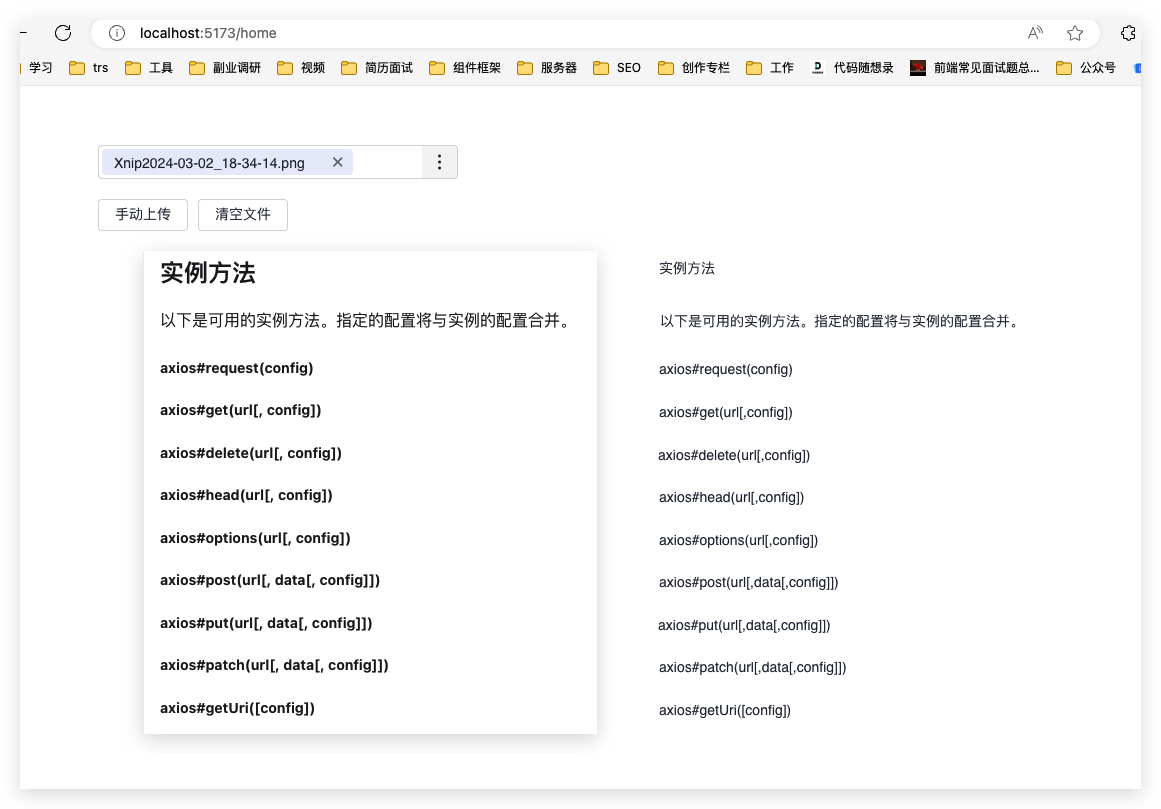
组件还是用的 devUI
至于怎么把文字跟图片定位的一模一样的,函数放这里,直接拿就行:
js
const returnStyle = (location) => {
return {
'top': location.top + 'px' ,
'width': location.width + 'px' ,
'left': location.left + 'px' ,
'height': location.height + 'px' ,
'position': 'absolute'
}
}
demo 会放到 GitHub 也可以直接去自取
GitHub:https://github.com/wangenze267
百度智能云-OCR: https://cloud.baidu.com/doc/OCR/index.html